
.webp)
at














Key Takeaways
OpenAI’s Agent Kit
By offering built-in orchestration, memory, function calling, and visual workflow tools, the Agent Kit turns the vision of agentic AI into a practical reality, enabling companies to move from experimentation to execution faster than ever before.
What's this article about?
This article explores how OpenAI’s new Agent Kit revolutionizes the way AI agents are built, simplifying orchestration, memory, and tool integration, while revealing a critical gap: the lack of end-to-end agent evaluation.
It highlights why validation-driven, human-in-the-loop frameworks are essential for building production-grade, trustworthy AI agents.
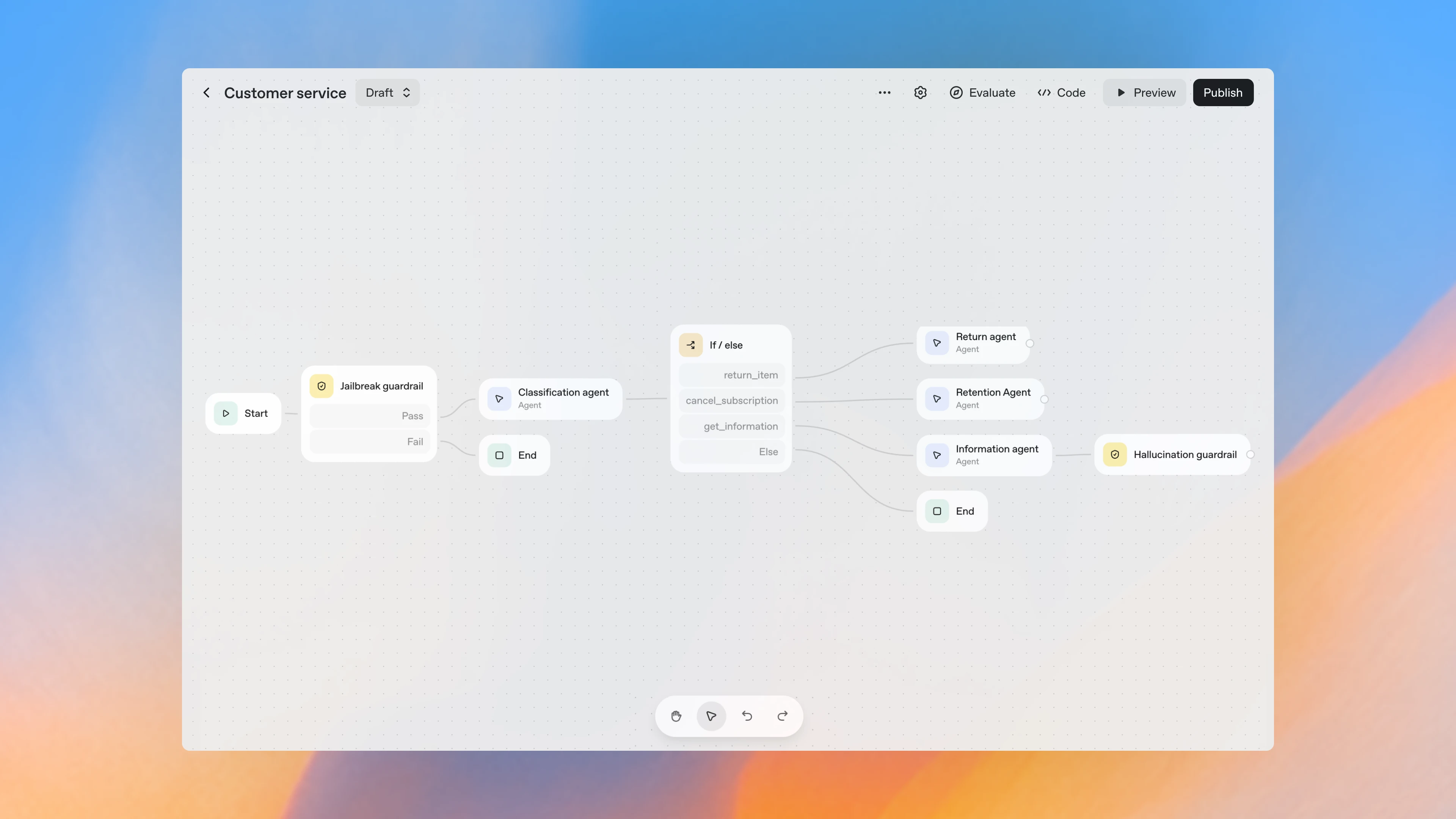
What are the risks of deploying AI agents too quickly?
This acceleration, however, comes with a new challenge: speed without evaluation is danger disguised as progress.
The Agent Kit allows anyone to build powerful agents, but without rigorous evaluation, observability, and human oversight, organizations risk deploying systems that are untested, unreliable, or even harmful.
Just because an AI agent can act autonomously doesn’t mean it should, at least, not without measurable safety checks and defined success criteria.
As we’ve seen with the Deloitte AI incident, a lack of evaluation can turn automation into liability overnight.
As Răzvan Bretoiu, Linnify's CTO, puts it:
"AI agents are still very much a black box.
You can evaluate prompts, but not the full end-to-end reasoning, and that’s a real limitation.
Right now, the only way to fine-tune behavior is through prompt engineering, which doesn’t tackle the core challenge of understanding how these systems actually work.
What’s really missing is a proper evaluation framework for the entire agentic system, one that allows business teams to improve agent accuracy through a human-in-the-loop approach. It’s a gap the entire industry should pay attention to!"

Why AI evaluation remains essential?
The real value of the Agent Kit isn’t in removing complexity; it’s in how teams manage that complexity responsibly.
At Linnify, we’ve been building agentic systems long before this release. Our evaluation-driven, human-in-the-loop framework ensures every AI agent we deploy is transparent, explainable, and aligned with operational standards.
Here’s how our approach strengthens what the Agent Kit enables:
- Pre-launch evaluation: We define measurable performance metrics (accuracy, latency, completeness) before agents ever go live.
- Human-in-the-loop validation: Domain experts continuously review and refine agent reasoning — ensuring decisions remain auditable and explainable.
- Observability and feedback loops: Real-time dashboards track performance and behavior, allowing continuous fine-tuning and compliance alignment.
- Safe scalability: As agents grow in complexity, our frameworks ensure each component is validated, monitored, and secure before integration.
This combination of Agent Kit + evaluation framework represents the future of trustworthy autonomy.
For more on this research foundation, see:
- Large Language Models with Human-In-The-Loop Validation - how HITL improves LLM reliability.
- Systematic Review of Validation Methods for AI Systems - frameworks for AI testing and trust.
- Human-in-the-loop or AI-in-the-loop? - strategies for aligning AI autonomy with human oversight.
- Best Practices for Human-in-the-Loop AI Agents - practical patterns for AI agent governance.
How can enterprises move from AI pilots to production-grade agents?
Many organizations have already experimented with LLMs and “AI copilots.”
But deploying production-grade agentic systems requires much more than APIs, it demands process maturity and rigorous validation.
Enterprises that make sure they integrate AI evaluation into their development early will build systems that are accurate, transparent, and compliant by design.
For example, our own AI deployments consistently reach 95%+ accuracy in production by combining human oversight with automated observability.
It’s not about building faster, it’s about building right.
What does OpenAI’s Agent Kit mean for enterprise leaders?
For enterprise leaders, OpenAI’s Agent Kit offers unprecedented potential to:
- Automate complex, multi-step business processes
- Personalize customer interactions at scale
- Integrate data-driven decision-making directly into operations
But potential only becomes progress when paired with responsibility.
But to capture this value responsibly, organizations need evaluation frameworks that keep autonomy aligned with business goals and ethics.
That’s where Linnify’s evaluation-driven approach bridges the gap between experimentation and reliable deployment.
How can businesses build trustworthy AI agents that scale?
The Agent Kit is more than a developer milestone, it’s the foundation for the next era of human-AI collaboration.
As enterprises rush to adopt it, the question isn’t who can build agents fastest.
It’s who can build trustworthy agents that scale safely.
At Linnify, we’re shaping that answer, through frameworks that make AI transparent, explainable, and production-ready.
Because in the new era of agentic AI, trust is the real innovation.
At Linnify, we help organizations design, build, and scale agentic AI systems using human-in-the-loop frameworks built for reliability and trust.
👉 Learn more about our approach to developing AI agents.
FAQ
1. What is OpenAI’s Agent Kit?
OpenAI’s Agent Kit is a development framework that allows teams to create production-grade AI agents with built-in orchestration, memory, evaluation, and integration capabilities. It simplifies the process of building agentic systems that can plan, reason, and act autonomously.
2. Why is evaluation important when using the Agent Kit?
Evaluation ensures that AI agents are reliable, explainable, and aligned with real-world expectations. Without human-in-the-loop oversight and measurable metrics, even powerful systems like those built with the Agent Kit can produce errors or biased results.
3. How does Linnify make AI agents production-grade?
At Linnify, we apply an evaluation-driven, human-in-the-loop framework that tests every agent’s performance before and after deployment. This includes defining clear success metrics, monitoring real-time behavior, and integrating human feedback for continuous improvement.
4. What are the benefits of using evaluation-driven AI in enterprises?
Evaluation-driven AI minimizes risk, improves compliance, and increases trust. For enterprise leaders, it ensures that automation enhances human decision-making instead of replacing it, resulting in systems that are scalable, transparent, and responsible.
Contributors
Speakers
Guest
Host
Share


Download
the full guide
Let’s build
your next digital product.
Subscribe to our newsletter
YOU MIGHT ALSO BE INTERESTED IN
RELATED ARTICLES


YOU MIGHT ALSO BE INTERESTED IN
